Creating customer segments using unsupervised learning
In this project, you will analyze a dataset containing data on various customers’ annual spending amounts (reported in monetary units) of diverse product categories for internal structure. One goal of this project is to best describe the variation in the different types of customers that a wholesale distributor interacts with. Doing so would equip the distributor with insight into how to best structure their delivery service to meet the needs of each customer.
The dataset for this project can be found on the UCI Machine Learning Repository. For the purposes of this project, the features 'Channel' and 'Region' will be excluded in the analysis — with focus instead on the six product categories recorded for customers.
Here is the code for this project which was a part of Udacity’s Machine Learning Engineer Nanodegree.
# Import libraries necessary for this projectimport numpy as npimport pandas as pdfrom IPython.display import display # Allows the use of display() for DataFrames
# Import supplementary visualizations code visuals.pyimport visuals as vs
# Pretty display for notebooks%matplotlib inline
# Load the wholesale customers datasettry: data = pd.read_csv("customers.csv") data.drop(['Region', 'Channel'], axis = 1, inplace = True) print "Wholesale customers dataset has {} samples with {} features each.".format(*data.shape)except: print "Dataset could not be loaded. Is the dataset missing?"Wholesale customers dataset has 440 samples with 6 features each.Data Exploration
In this section, you will begin exploring the data through visualizations and code to understand how each feature is related to the others. You will observe a statistical description of the dataset, consider the relevance of each feature, and select a few sample data points from the dataset which you will track through the course of this project.
Run the code block below to observe a statistical description of the dataset. Note that the dataset is composed of six important product categories: ‘Fresh’, ‘Milk’, ‘Grocery’, ‘Frozen’, ‘Detergents_Paper’, and ‘Delicatessen’. Consider what each category represents in terms of products you could purchase.
# Display a description of the datasetdisplay(data.describe())| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| count | 440.000000 | 440.000000 | 440.000000 | 440.000000 | 440.000000 | 440.000000 |
| mean | 12000.297727 | 5796.265909 | 7951.277273 | 3071.931818 | 2881.493182 | 1524.870455 |
| std | 12647.328865 | 7380.377175 | 9503.162829 | 4854.673333 | 4767.854448 | 2820.105937 |
| min | 3.000000 | 55.000000 | 3.000000 | 25.000000 | 3.000000 | 3.000000 |
| 25% | 3127.750000 | 1533.000000 | 2153.000000 | 742.250000 | 256.750000 | 408.250000 |
| 50% | 8504.000000 | 3627.000000 | 4755.500000 | 1526.000000 | 816.500000 | 965.500000 |
| 75% | 16933.750000 | 7190.250000 | 10655.750000 | 3554.250000 | 3922.000000 | 1820.250000 |
| max | 112151.000000 | 73498.000000 | 92780.000000 | 60869.000000 | 40827.000000 | 47943.000000 |
Implementation: Selecting Samples
To get a better understanding of the customers and how their data will transform through the analysis, it would be best to select a few sample data points and explore them in more detail. In the code block below, add three indices of your choice to the indices list which will represent the customers to track. It is suggested to try different sets of samples until you obtain customers that vary significantly from one another.
# TODO: Select three indices of your choice you wish to sample from the datasetindices = [0]
search_index = 0
def get_dict(index): return dict(data.loc[index])
def is_different(dict1, dict2): for key, value in dict1.items(): if abs(dict2[key] - value) < abs(min(dict2[key], value)): return False return True
while search_index < 400 and len(indices) <= 2: search_index += 1 num_different = sum([1 for index in indices if is_different(get_dict(index), get_dict(search_index))]) if num_different == len(indices): indices.append(search_index)
print indices
# Create a DataFrame of the chosen samplessamples = pd.DataFrame(data.loc[indices], columns = data.keys()).reset_index(drop = True)print "Chosen samples of wholesale customers dataset:"display(samples)[0, 21, 47]Chosen samples of wholesale customers dataset:| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| 0 | 12669 | 9656 | 7561 | 214 | 2674 | 1338 |
| 1 | 5567 | 871 | 2010 | 3383 | 375 | 569 |
| 2 | 44466 | 54259 | 55571 | 7782 | 24171 | 6465 |
Question 1
Consider the total purchase cost of each product category and the statistical description of the dataset above for your sample customers.
What kind of establishment (customer) could each of the three samples you’ve chosen represent?
Hint: Examples of establishments include places like markets, cafes, and retailers, among many others. Avoid using names for establishments, such as saying “McDonalds” when describing a sample customer as a restaurant.
Answer:
First customer:
This customer buys greater than average units of everything except frozen items- could be a restaurant cooking fresh items and needing lots of detergent for cleaning.
Second customer:
This customer buys a lot of frozen items but less than 25 percentile of other items- could be a fast food establishment serving food quickly using frozen items.
Third customer:
This customer buys everything in bulk, much greater than 75 percentile- must be a supermarket.
Implementation: Feature Relevance
One interesting thought to consider is if one (or more) of the six product categories is actually relevant for understanding customer purchasing. That is to say, is it possible to determine whether customers purchasing some amount of one category of products will necessarily purchase some proportional amount of another category of products? We can make this determination quite easily by training a supervised regression learner on a subset of the data with one feature removed, and then score how well that model can predict the removed feature.
In the code block below, you will need to implement the following:
- Assign
new_dataa copy of the data by removing a feature of your choice using theDataFrame.dropfunction. - Use
sklearn.cross_validation.train_test_splitto split the dataset into training and testing sets.- Use the removed feature as your target label. Set a
test_sizeof0.25and set arandom_state.
- Use the removed feature as your target label. Set a
- Import a decision tree regressor, set a
random_state, and fit the learner to the training data. - Report the prediction score of the testing set using the regressor’s
scorefunction.
# TODO: Make a copy of the DataFrame, using the 'drop' function to drop the given featuredropped = "Grocery"new_data = data.drop(dropped, 1)
# TODO: Split the data into training and testing sets using the given feature as the targetfrom sklearn.cross_validation import train_test_splitX_train, X_test, y_train, y_test = train_test_split(new_data, data[dropped], test_size=0.25, random_state=12)
# TODO: Create a decision tree regressor and fit it to the training setfrom sklearn.tree import DecisionTreeRegressorregressor = DecisionTreeRegressor(random_state=12)regressor.fit(X_train, y_train)
# TODO: Report the score of the prediction using the testing setscore = regressor.score(X_test, y_test)print (score)0.800233654655Question 2
Which feature did you attempt to predict? What was the reported prediction score? Is this feature is necessary for identifying customers’ spending habits?
Hint: The coefficient of determination, R^2, is scored between 0 and 1, with 1 being a perfect fit. A negative R^2 implies the model fails to fit the data.
Answer:
I attempted to predict Grocery.
Prediction score was a high 0.8- it is safe to conclude that this feature is not necessary for identifying customer’s spending habits.
Visualize Feature Distributions
To get a better understanding of the dataset, we can construct a scatter matrix of each of the six product features present in the data. If you found that the feature you attempted to predict above is relevant for identifying a specific customer, then the scatter matrix below may not show any correlation between that feature and the others. Conversely, if you believe that feature is not relevant for identifying a specific customer, the scatter matrix might show a correlation between that feature and another feature in the data. Run the code block below to produce a scatter matrix.
# Produce a scatter matrix for each pair of features in the datapd.scatter_matrix(data, alpha = 0.3, figsize = (14,8), diagonal = 'kde');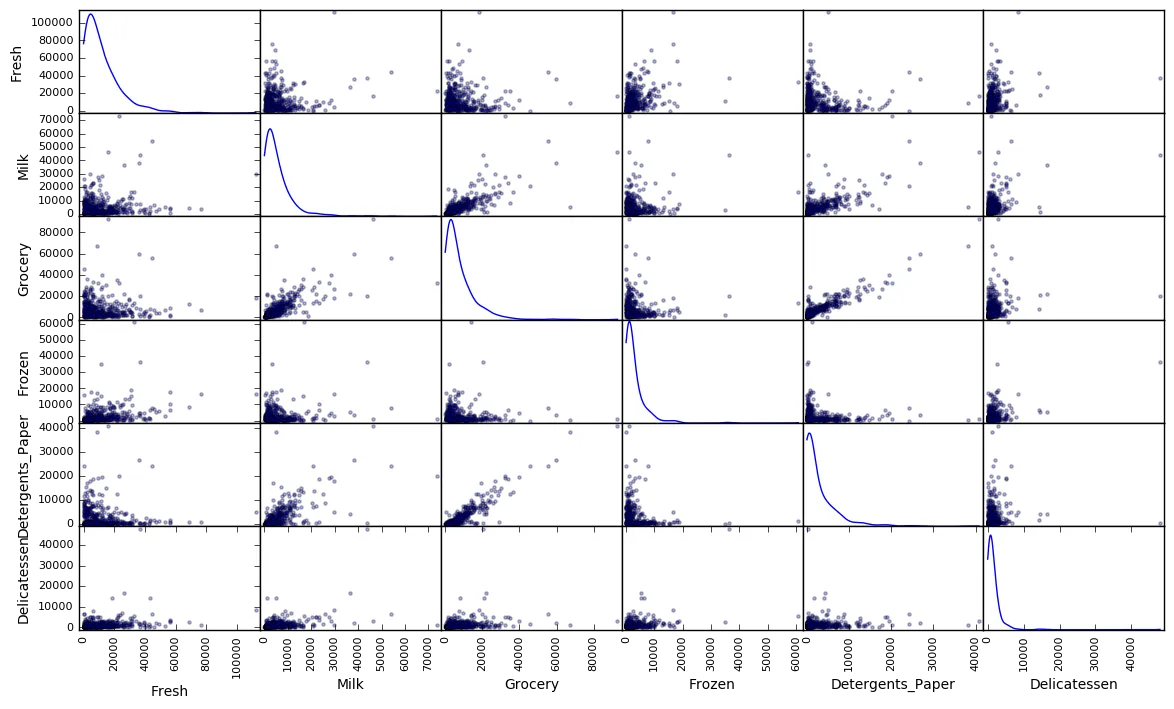
Question 3
Are there any pairs of features which exhibit some degree of correlation? Does this confirm or deny your suspicions about the relevance of the feature you attempted to predict? How is the data for those features distributed?
Hint: Is the data normally distributed? Where do most of the data points lie?
Answer:
Grocery & Detergents_Paper and Grocery & Milk seem to be correlated to a certain degree.
This confirms my suspision that Grocery can be dropped- information to be gained from it is captured in other features.
The data is not normally distributed- most of the data is closer to 0.
Data Preprocessing
In this section, you will preprocess the data to create a better representation of customers by performing a scaling on the data and detecting (and optionally removing) outliers. Preprocessing data is often times a critical step in assuring that results you obtain from your analysis are significant and meaningful.
Implementation: Feature Scaling
If data is not normally distributed, especially if the mean and median vary significantly (indicating a large skew), it is most often appropriate to apply a non-linear scaling — particularly for financial data. One way to achieve this scaling is by using a Box-Cox test, which calculates the best power transformation of the data that reduces skewness. A simpler approach which can work in most cases would be applying the natural logarithm.
In the code block below, you will need to implement the following:
- Assign a copy of the data to
log_dataafter applying logarithmic scaling. Use thenp.logfunction for this. - Assign a copy of the sample data to
log_samplesafter applying logarithmic scaling. Again, usenp.log.
# TODO: Scale the data using the natural logarithmlog_data = np.log(data)
# TODO: Scale the sample data using the natural logarithmlog_samples = np.log(samples)
# Produce a scatter matrix for each pair of newly-transformed featurespd.scatter_matrix(log_data, alpha = 0.3, figsize = (14,8), diagonal = 'kde');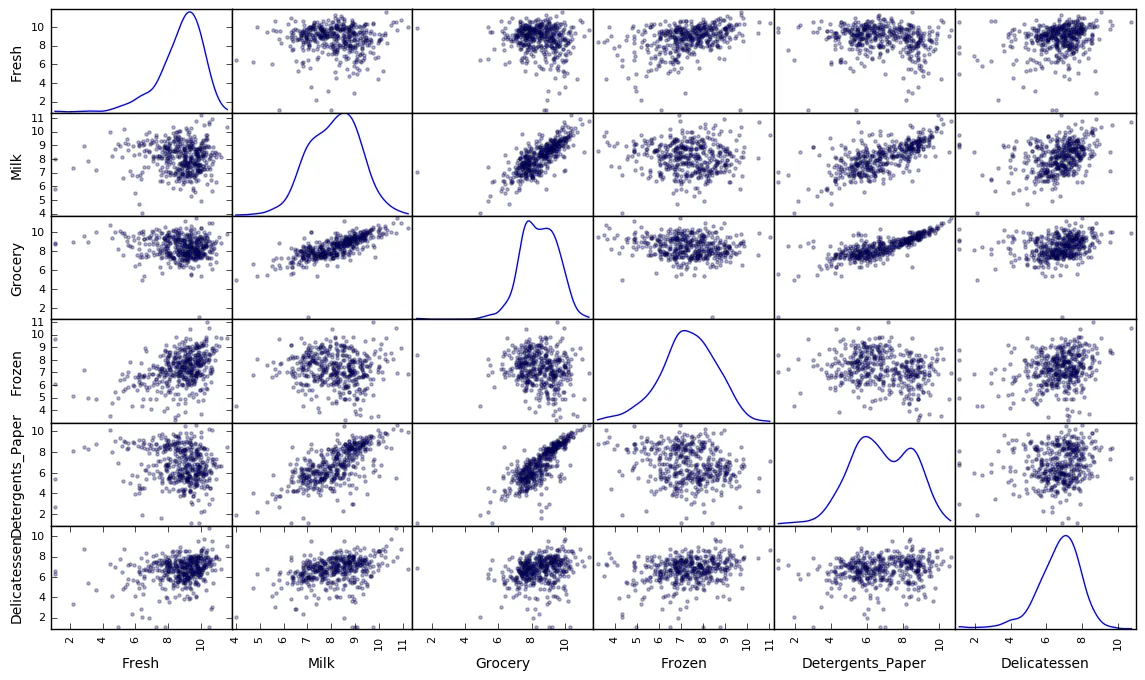
Observation
After applying a natural logarithm scaling to the data, the distribution of each feature should appear much more normal. For any pairs of features you may have identified earlier as being correlated, observe here whether that correlation is still present (and whether it is now stronger or weaker than before).
Run the code below to see how the sample data has changed after having the natural logarithm applied to it.
# Display the log-transformed sample datadisplay(log_samples)| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| 0 | 9.446913 | 9.175335 | 8.930759 | 5.365976 | 7.891331 | 7.198931 |
| 1 | 8.624612 | 6.769642 | 7.605890 | 8.126518 | 5.926926 | 6.343880 |
| 2 | 10.702480 | 10.901524 | 10.925417 | 8.959569 | 10.092909 | 8.774158 |
Implementation: Outlier Detection
Detecting outliers in the data is extremely important in the data preprocessing step of any analysis. The presence of outliers can often skew results which take into consideration these data points. There are many “rules of thumb” for what constitutes an outlier in a dataset. Here, we will use Tukey’s Method for identfying outliers: An outlier step is calculated as 1.5 times the interquartile range (IQR). A data point with a feature that is beyond an outlier step outside of the IQR for that feature is considered abnormal.
In the code block below, you will need to implement the following:
- Assign the value of the 25th percentile for the given feature to
Q1. Usenp.percentilefor this. - Assign the value of the 75th percentile for the given feature to
Q3. Again, usenp.percentile. - Assign the calculation of an outlier step for the given feature to
step. - Optionally remove data points from the dataset by adding indices to the
outlierslist.
NOTE: If you choose to remove any outliers, ensure that the sample data does not contain any of these points!
Once you have performed this implementation, the dataset will be stored in the variable good_data.
all_outliers = []outliers = set()
# For each feature find the data points with extreme high or low valuesfor feature in log_data.keys():
# TODO: Calculate Q1 (25th percentile of the data) for the given feature Q1 = np.percentile(log_data[feature], 25)
# TODO: Calculate Q3 (75th percentile of the data) for the given feature Q3 = np.percentile(log_data[feature], 75)
# TODO: Use the interquartile range to calculate an outlier step (1.5 times the interquartile range) step = 1.5 * (Q3- Q1)
# Display the outliers print "Data points considered outliers for the feature '{}':".format(feature) current_outliers = log_data[~((log_data[feature] >= Q1 - step) & (log_data[feature] <= Q3 + step))] for outlier in current_outliers.index.tolist(): if outlier in all_outliers: outliers.add(outlier) else: all_outliers.append(outlier) display(current_outliers)
# OPTIONAL: Select the indices for data points you wish to removeoutliers = list(outliers)print outliersprint len(all_outliers)
# Remove the outliers, if any were specifiedgood_data = log_data.drop(log_data.index[outliers]).reset_index(drop = True)Data points considered outliers for the feature 'Fresh':| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| 65 | 4.442651 | 9.950323 | 10.732651 | 3.583519 | 10.095388 | 7.260523 |
| 66 | 2.197225 | 7.335634 | 8.911530 | 5.164786 | 8.151333 | 3.295837 |
| 81 | 5.389072 | 9.163249 | 9.575192 | 5.645447 | 8.964184 | 5.049856 |
| 95 | 1.098612 | 7.979339 | 8.740657 | 6.086775 | 5.407172 | 6.563856 |
| 96 | 3.135494 | 7.869402 | 9.001839 | 4.976734 | 8.262043 | 5.379897 |
| 128 | 4.941642 | 9.087834 | 8.248791 | 4.955827 | 6.967909 | 1.098612 |
| 171 | 5.298317 | 10.160530 | 9.894245 | 6.478510 | 9.079434 | 8.740337 |
| 193 | 5.192957 | 8.156223 | 9.917982 | 6.865891 | 8.633731 | 6.501290 |
| 218 | 2.890372 | 8.923191 | 9.629380 | 7.158514 | 8.475746 | 8.759669 |
| 304 | 5.081404 | 8.917311 | 10.117510 | 6.424869 | 9.374413 | 7.787382 |
| 305 | 5.493061 | 9.468001 | 9.088399 | 6.683361 | 8.271037 | 5.351858 |
| 338 | 1.098612 | 5.808142 | 8.856661 | 9.655090 | 2.708050 | 6.309918 |
| 353 | 4.762174 | 8.742574 | 9.961898 | 5.429346 | 9.069007 | 7.013016 |
| 355 | 5.247024 | 6.588926 | 7.606885 | 5.501258 | 5.214936 | 4.844187 |
| 357 | 3.610918 | 7.150701 | 10.011086 | 4.919981 | 8.816853 | 4.700480 |
| 412 | 4.574711 | 8.190077 | 9.425452 | 4.584967 | 7.996317 | 4.127134 |
Data points considered outliers for the feature 'Milk':| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| 86 | 10.039983 | 11.205013 | 10.377047 | 6.894670 | 9.906981 | 6.805723 |
| 98 | 6.220590 | 4.718499 | 6.656727 | 6.796824 | 4.025352 | 4.882802 |
| 154 | 6.432940 | 4.007333 | 4.919981 | 4.317488 | 1.945910 | 2.079442 |
| 356 | 10.029503 | 4.897840 | 5.384495 | 8.057377 | 2.197225 | 6.306275 |
Data points considered outliers for the feature 'Grocery':| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| 75 | 9.923192 | 7.036148 | 1.098612 | 8.390949 | 1.098612 | 6.882437 |
| 154 | 6.432940 | 4.007333 | 4.919981 | 4.317488 | 1.945910 | 2.079442 |
Data points considered outliers for the feature 'Frozen':| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| 38 | 8.431853 | 9.663261 | 9.723703 | 3.496508 | 8.847360 | 6.070738 |
| 57 | 8.597297 | 9.203618 | 9.257892 | 3.637586 | 8.932213 | 7.156177 |
| 65 | 4.442651 | 9.950323 | 10.732651 | 3.583519 | 10.095388 | 7.260523 |
| 145 | 10.000569 | 9.034080 | 10.457143 | 3.737670 | 9.440738 | 8.396155 |
| 175 | 7.759187 | 8.967632 | 9.382106 | 3.951244 | 8.341887 | 7.436617 |
| 264 | 6.978214 | 9.177714 | 9.645041 | 4.110874 | 8.696176 | 7.142827 |
| 325 | 10.395650 | 9.728181 | 9.519735 | 11.016479 | 7.148346 | 8.632128 |
| 420 | 8.402007 | 8.569026 | 9.490015 | 3.218876 | 8.827321 | 7.239215 |
| 429 | 9.060331 | 7.467371 | 8.183118 | 3.850148 | 4.430817 | 7.824446 |
| 439 | 7.932721 | 7.437206 | 7.828038 | 4.174387 | 6.167516 | 3.951244 |
Data points considered outliers for the feature 'Detergents_Paper':| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| 75 | 9.923192 | 7.036148 | 1.098612 | 8.390949 | 1.098612 | 6.882437 |
| 161 | 9.428190 | 6.291569 | 5.645447 | 6.995766 | 1.098612 | 7.711101 |
Data points considered outliers for the feature 'Delicatessen':| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| 66 | 2.197225 | 7.335634 | 8.911530 | 5.164786 | 8.151333 | 3.295837 |
| 109 | 7.248504 | 9.724899 | 10.274568 | 6.511745 | 6.728629 | 1.098612 |
| 128 | 4.941642 | 9.087834 | 8.248791 | 4.955827 | 6.967909 | 1.098612 |
| 137 | 8.034955 | 8.997147 | 9.021840 | 6.493754 | 6.580639 | 3.583519 |
| 142 | 10.519646 | 8.875147 | 9.018332 | 8.004700 | 2.995732 | 1.098612 |
| 154 | 6.432940 | 4.007333 | 4.919981 | 4.317488 | 1.945910 | 2.079442 |
| 183 | 10.514529 | 10.690808 | 9.911952 | 10.505999 | 5.476464 | 10.777768 |
| 184 | 5.789960 | 6.822197 | 8.457443 | 4.304065 | 5.811141 | 2.397895 |
| 187 | 7.798933 | 8.987447 | 9.192075 | 8.743372 | 8.148735 | 1.098612 |
| 203 | 6.368187 | 6.529419 | 7.703459 | 6.150603 | 6.860664 | 2.890372 |
| 233 | 6.871091 | 8.513988 | 8.106515 | 6.842683 | 6.013715 | 1.945910 |
| 285 | 10.602965 | 6.461468 | 8.188689 | 6.948897 | 6.077642 | 2.890372 |
| 289 | 10.663966 | 5.655992 | 6.154858 | 7.235619 | 3.465736 | 3.091042 |
| 343 | 7.431892 | 8.848509 | 10.177932 | 7.283448 | 9.646593 | 3.610918 |
[128, 65, 154, 75, 66]42Question 4
Are there any data points considered outliers for more than one feature based on the definition above? Should these data points be removed from the dataset? If any data points were added to the outliers list to be removed, explain why.
Answer:
Yes, 5 datapoints were outliers for more than one feature and hence were removed as they may cause the algorithm to overfit.
42 datapoints were outliers for at least one feature, but this is a significant amount of the data (around 10%). Removing a data point for being an outlier for just one feature might result in losing valuable information from the other features.
Feature Transformation
In this section you will use principal component analysis (PCA) to draw conclusions about the underlying structure of the wholesale customer data. Since using PCA on a dataset calculates the dimensions which best maximize variance, we will find which compound combinations of features best describe customers.
Implementation: PCA
Now that the data has been scaled to a more normal distribution and has had any necessary outliers removed, we can now apply PCA to the good_data to discover which dimensions about the data best maximize the variance of features involved. In addition to finding these dimensions, PCA will also report the explained variance ratio of each dimension — how much variance within the data is explained by that dimension alone. Note that a component (dimension) from PCA can be considered a new “feature” of the space, however it is a composition of the original features present in the data.
In the code block below, you will need to implement the following:
- Import
sklearn.decomposition.PCAand assign the results of fitting PCA in six dimensions withgood_datatopca. - Apply a PCA transformation of
log_samplesusingpca.transform, and assign the results topca_samples.
# TODO: Apply PCA by fitting the good data with the same number of dimensions as featuresfrom sklearn.decomposition import PCApca = PCA(n_components=len(good_data.columns)).fit(good_data)
# TODO: Transform log_samples using the PCA fit abovepca_samples = pca.transform(log_samples)
# Generate PCA results plotpca_results = vs.pca_results(good_data, pca)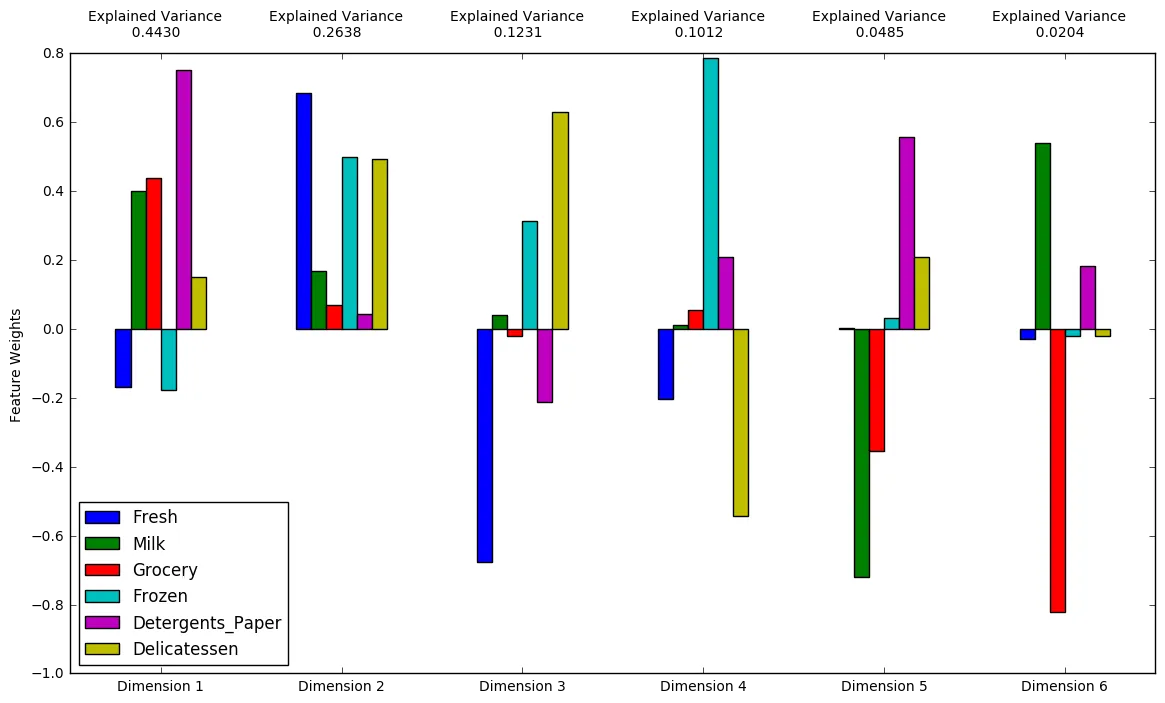
Question 5
How much variance in the data is explained in total by the first and second principal component? What about the first four principal components? Using the visualization provided above, discuss what the first four dimensions best represent in terms of customer spending.
Hint: A positive increase in a specific dimension corresponds with an increase of the positive-weighted features and a decrease of the negative-weighted features. The rate of increase or decrease is based on the indivdual feature weights.
Answer:
Variance explained by:
- first two: 0.7068
- first four: 0.9311
Dimensions:
Each dimension does not represent a different type of customer. However, each dimension does assign values to different types of products, which in turn could help differentiate different type of customers. For all dimensions, high value (+ve) for a product means high volume of purchase for that product and low value (-ve) means low volume. Customers with a high value for one of the PCA dimensions and low values for the others after the feature transformation could be interpreted as below for each of the first four dimensions respectively:
- Lots of detergents and a decent amout of milk, grocery and delicatessen- could represent supermarkets.
- Little bit of everything with a lot of Fresh, frozen and Delicatessen- could represent restaurants.
- Only significant purchases are Delicatessen and frozen items- could represent local delis.
- Lots of frozen items and some detergents- could represent fast food chains.
Observation
Run the code below to see how the log-transformed sample data has changed after having a PCA transformation applied to it in six dimensions. Observe the numerical value for the first four dimensions of the sample points. Consider if this is consistent with your initial interpretation of the sample points.
# Display sample log-data after having a PCA transformation applieddisplay(pd.DataFrame(np.round(pca_samples, 4), columns = pca_results.index.values))| Dimension 1 | Dimension 2 | Dimension 3 | Dimension 4 | Dimension 5 | Dimension 6 | |
|---|---|---|---|---|---|---|
| 0 | 1.7580 | -0.0097 | -0.9590 | -1.6824 | -0.2680 | 0.3891 |
| 1 | -1.7467 | -0.1939 | 0.2753 | 0.6012 | 0.7470 | -0.1974 |
| 2 | 4.3646 | 3.9519 | -0.1229 | 0.6240 | -0.5379 | -0.0551 |
Implementation: Dimensionality Reduction
When using principal component analysis, one of the main goals is to reduce the dimensionality of the data — in effect, reducing the complexity of the problem. Dimensionality reduction comes at a cost: Fewer dimensions used implies less of the total variance in the data is being explained. Because of this, the cumulative explained variance ratio is extremely important for knowing how many dimensions are necessary for the problem. Additionally, if a signifiant amount of variance is explained by only two or three dimensions, the reduced data can be visualized afterwards.
In the code block below, you will need to implement the following:
- Assign the results of fitting PCA in two dimensions with
good_datatopca. - Apply a PCA transformation of
good_datausingpca.transform, and assign the results toreduced_data. - Apply a PCA transformation of
log_samplesusingpca.transform, and assign the results topca_samples.
# TODO: Apply PCA by fitting the good data with only two dimensionspca = PCA(n_components=2).fit(good_data)
# TODO: Transform the good data using the PCA fit abovereduced_data = pca.transform(good_data)
# TODO: Transform log_samples using the PCA fit abovepca_samples = pca.transform(log_samples)
# Create a DataFrame for the reduced datareduced_data = pd.DataFrame(reduced_data, columns = ['Dimension 1', 'Dimension 2'])Observation
Run the code below to see how the log-transformed sample data has changed after having a PCA transformation applied to it using only two dimensions. Observe how the values for the first two dimensions remains unchanged when compared to a PCA transformation in six dimensions.
# Display sample log-data after applying PCA transformation in two dimensionsdisplay(pd.DataFrame(np.round(pca_samples, 4), columns = ['Dimension 1', 'Dimension 2']))| Dimension 1 | Dimension 2 | |
|---|---|---|
| 0 | 1.7580 | -0.0097 |
| 1 | -1.7467 | -0.1939 |
| 2 | 4.3646 | 3.9519 |
Visualizing a Biplot
A biplot is a scatterplot where each data point is represented by its scores along the principal components. The axes are the principal components (in this case Dimension 1 and Dimension 2). In addition, the biplot shows the projection of the original features along the components. A biplot can help us interpret the reduced dimensions of the data, and discover relationships between the principal components and original features.
Run the code cell below to produce a biplot of the reduced-dimension data.
# Create a biplotvs.biplot(good_data, reduced_data, pca)<matplotlib.axes._subplots.AxesSubplot at 0xd9374e0>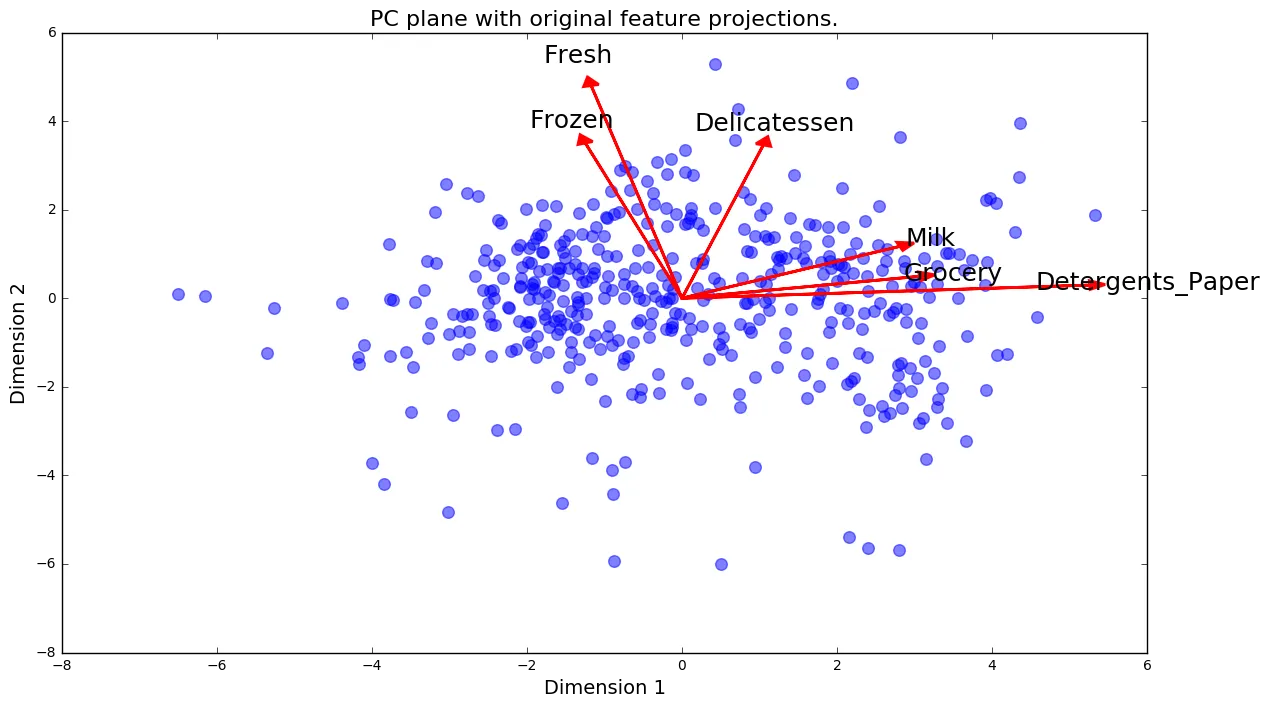
Observation
Once we have the original feature projections (in red), it is easier to interpret the relative position of each data point in the scatterplot. For instance, a point the lower right corner of the figure will likely correspond to a customer that spends a lot on 'Milk', 'Grocery' and 'Detergents_Paper', but not so much on the other product categories.
From the biplot, which of the original features are most strongly correlated with the first component? What about those that are associated with the second component? Do these observations agree with the pca_results plot you obtained earlier?
Clustering
In this section, you will choose to use either a K-Means clustering algorithm or a Gaussian Mixture Model clustering algorithm to identify the various customer segments hidden in the data. You will then recover specific data points from the clusters to understand their significance by transforming them back into their original dimension and scale.
Question 6
What are the advantages to using a K-Means clustering algorithm? What are the advantages to using a Gaussian Mixture Model clustering algorithm? Given your observations about the wholesale customer data so far, which of the two algorithms will you use and why?
Answer:
K-means advantages:
- Simple to implement
- Easy to interpret results
- Fast
Gaussian Mixture Model advantages:
- Soft classification- one point can belong to multiple clusters
- More flexible
- As this algorithm maximizes only the likelihood, it will not bias the means towards zero, or bias the cluster sizes to have specific structures that might or might not apply. [1]
I would use Gaussian Mixture Model because I am not sure of the number of clusters from the plot above.
Points are close to each other so soft clustering is the way to go.
Implementation: Creating Clusters
Depending on the problem, the number of clusters that you expect to be in the data may already be known. When the number of clusters is not known a priori, there is no guarantee that a given number of clusters best segments the data, since it is unclear what structure exists in the data — if any. However, we can quantify the “goodness” of a clustering by calculating each data point’s silhouette coefficient. The silhouette coefficient for a data point measures how similar it is to its assigned cluster from -1 (dissimilar) to 1 (similar). Calculating the mean silhouette coefficient provides for a simple scoring method of a given clustering.
In the code block below, you will need to implement the following:
- Fit a clustering algorithm to the
reduced_dataand assign it toclusterer. - Predict the cluster for each data point in
reduced_datausingclusterer.predictand assign them topreds. - Find the cluster centers using the algorithm’s respective attribute and assign them to
centers. - Predict the cluster for each sample data point in
pca_samplesand assign themsample_preds. - Import
sklearn.metrics.silhouette_scoreand calculate the silhouette score ofreduced_dataagainstpreds.- Assign the silhouette score to
scoreand print the result.
- Assign the silhouette score to
# TODO: Apply your clustering algorithm of choice to the reduced datafrom sklearn.mixture import GMMfrom sklearn.metrics import silhouette_scorescores = {}
# for components in xrange(2, 50, 4):for components in xrange(50, 1, -4): clusterer = GMM(n_components=components).fit(reduced_data)
# TODO: Predict the cluster for each data point preds = clusterer.predict(reduced_data)
# TODO: Find the cluster centers centers = clusterer.means_
# TODO: Predict the cluster for each transformed sample data point sample_preds = clusterer.predict(pca_samples)
# TODO: Calculate the mean silhouette coefficient for the number of clusters chosen scores[components] = silhouette_score(reduced_data, preds)
for components in sorted(scores.iterkeys()): print "%s: %s" % (components, scores[components])2: 0.4118188643866: 0.28606685812910: 0.28135274506614: 0.25431514897818: 0.20174712042822: 0.23540203224926: 0.1801151003330: 0.15740739468634: 0.086932492424238: 0.10474221537942: 0.12022435588146: 0.1018112740850: 0.0848926572289Question 7
Report the silhouette score for several cluster numbers you tried. Of these, which number of clusters has the best silhouette score?
Answer:
Some scores are reported below, best silhoutte score was when number of clusters = 2.
2: 0.411818864386
6: 0.286066858129
10: 0.281352745066
14: 0.254315148978
18: 0.201747120428
22: 0.235402032249
26: 0.18011510033
30: 0.157407394686
34: 0.0869324924242
38: 0.104742215379
42: 0.120224355881
46: 0.10181127408
50: 0.0848926572289
Cluster Visualization
Once you’ve chosen the optimal number of clusters for your clustering algorithm using the scoring metric above, you can now visualize the results by executing the code block below. Note that, for experimentation purposes, you are welcome to adjust the number of clusters for your clustering algorithm to see various visualizations. The final visualization provided should, however, correspond with the optimal number of clusters.
# Display the results of the clustering from implementationvs.cluster_results(reduced_data, preds, centers, pca_samples)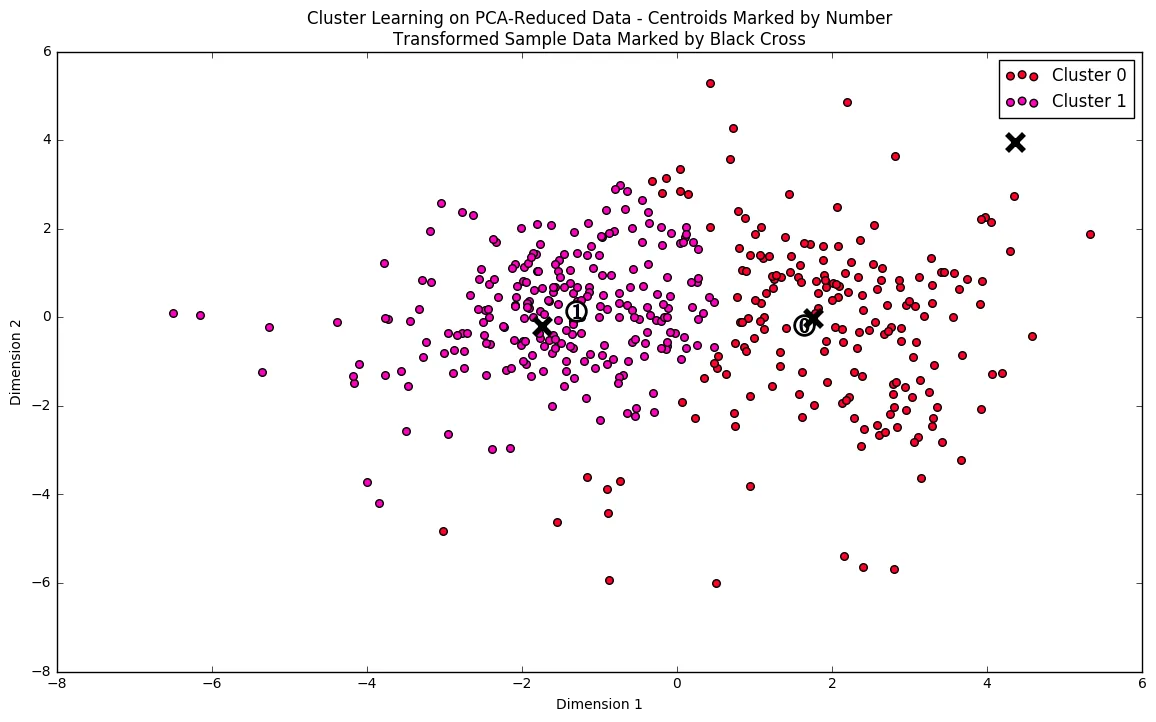
Implementation: Data Recovery
Each cluster present in the visualization above has a central point. These centers (or means) are not specifically data points from the data, but rather the averages of all the data points predicted in the respective clusters. For the problem of creating customer segments, a cluster’s center point corresponds to the average customer of that segment. Since the data is currently reduced in dimension and scaled by a logarithm, we can recover the representative customer spending from these data points by applying the inverse transformations.
In the code block below, you will need to implement the following:
- Apply the inverse transform to
centersusingpca.inverse_transformand assign the new centers tolog_centers. - Apply the inverse function of
np.logtolog_centersusingnp.expand assign the true centers totrue_centers.
# TODO: Inverse transform the centerslog_centers = pca.inverse_transform(centers)
# TODO: Exponentiate the centerstrue_centers = np.exp(log_centers)
# Display the true centerssegments = ['Segment {}'.format(i) for i in range(0,len(centers))]true_centers = pd.DataFrame(np.round(true_centers), columns = data.keys())true_centers.index = segmentsdisplay(true_centers)| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| Segment 0 | 4316.0 | 6347.0 | 9555.0 | 1036.0 | 3046.0 | 945.0 |
| Segment 1 | 8812.0 | 2052.0 | 2689.0 | 2058.0 | 337.0 | 712.0 |
Question 8
Consider the total purchase cost of each product category for the representative data points above, and reference the statistical description of the dataset at the beginning of this project. What set of establishments could each of the customer segments represent?
Hint: A customer who is assigned to 'Cluster X' should best identify with the establishments represented by the feature set of 'Segment X'.
Answer:
Segment 0:
Delicatessen purchases are close to the average while milk/grocery/detergent/paper purchases are close to 75th percentile.
This segment likely represents supermarkets/local delis because they buy lots of grocery/milk/detergent/paper to resell.
Segment 1:
Greater than average amounts of fresh and frozen products are purchased- likely to prepare food. Purchase of remaining products falls between 25th percentile and 50th percentile- this means they are likely utilized instead of being resold.
This segment likely represents restaurants/fast food chains.
Question 9
For each sample point, which customer segment from Question 8 best represents it? Are the predictions for each sample point consistent with this?
Run the code block below to find which cluster each sample point is predicted to be.
# Display the predictionsfor i, pred in enumerate(sample_preds): print "Sample point", i, "predicted to be in Cluster", predSample point 0 predicted to be in Cluster 0Sample point 1 predicted to be in Cluster 1Sample point 2 predicted to be in Cluster 0Answer:
Sample 0:
Comparing with the cluster centers from above, all products except ‘Fresh’ are closer to the cluster center for segment 0. This means that the model is likely going to predict that this sample belongs to segment 0 (supermarket). My initial prediction was that it was restaurant but the model predicts that it is a supermarket. It does makes sense because all items are bought in quantities greater than average- a restaurant wouldn’t need so much delicatessen/milk.
Sample 1:
Comparing with the cluster centers from above, all products except ‘Fresh’ are closer to the cluster center for segment 1. This means that the model is likely going to predict that this sample belongs to segment 1 (restaurant). My initial prediction was inline with the model’s that it could be a fast food establishemnt given the greater than average amount of frozen and fresh purchases.
Sample 2:
Comparing with the cluster centers from above, all products except ‘Fresh’ and ‘Frozen’ are closer to the cluster center for segment 0. This means that the model is likely going to predict that this sample belongs to segment 0 (supermarket). My initial prediction was inline with the model’s that it could be a supermarket purchasing all types of products in bulk and reselling them.
Conclusion
In this final section, you will investigate ways that you can make use of the clustered data. First, you will consider how the different groups of customers, the customer segments, may be affected differently by a specific delivery scheme. Next, you will consider how giving a label to each customer (which segment that customer belongs to) can provide for additional features about the customer data. Finally, you will compare the customer segments to a hidden variable present in the data, to see whether the clustering identified certain relationships.
Question 10
Companies will often run A/B tests when making small changes to their products or services to determine whether making that change will affect its customers positively or negatively. The wholesale distributor is considering changing its delivery service from currently 5 days a week to 3 days a week. However, the distributor will only make this change in delivery service for customers that react positively. How can the wholesale distributor use the customer segments to determine which customers, if any, would react positively to the change in delivery service?
Hint: Can we assume the change affects all customers equally? How can we determine which group of customers it affects the most?
Answer:
Segment 1 customers buy more fresh products and are likely to react negatively to a reduction in the delivery frequecy as this means the products aren’t as fresh anymore.
Here’s a good way to run the A/B test, now that the wholesale distributor knows there are two segments:
- Split each segment into two equal groups- splitting them randomly.
- For each segment, deliver 5 days a week to one group and 3 days a week to another.
- Compare the reaction to the other group from the same segment.
This lets the wholesale distributor obtain better insights by compare results with the same type of customers.
Question 11
Additional structure is derived from originally unlabeled data when using clustering techniques. Since each customer has a customer segment it best identifies with (depending on the clustering algorithm applied), we can consider ‘customer segment’ as an engineered feature for the data. Assume the wholesale distributor recently acquired ten new customers and each provided estimates for anticipated annual spending of each product category. Knowing these estimates, the wholesale distributor wants to classify each new customer to a customer segment to determine the most appropriate delivery service.
How can the wholesale distributor label the new customers using only their estimated product spending and the customer segment data?
Hint: A supervised learner could be used to train on the original customers. What would be the target variable?
Answer:
Training the original dataset using a supervised learner with total spending of each category as input features and ‘customer segment’ as the target variable will give us a model that can predict the customer segment for new customers like the ten new ones in the above example based on their estimated annual spending in each category.
Visualizing Underlying Distributions
At the beginning of this project, it was discussed that the 'Channel' and 'Region' features would be excluded from the dataset so that the customer product categories were emphasized in the analysis. By reintroducing the 'Channel' feature to the dataset, an interesting structure emerges when considering the same PCA dimensionality reduction applied earlier to the original dataset.
Run the code block below to see how each data point is labeled either 'HoReCa' (Hotel/Restaurant/Cafe) or 'Retail' the reduced space. In addition, you will find the sample points are circled in the plot, which will identify their labeling.
# Display the clustering results based on 'Channel' datavs.channel_results(reduced_data, outliers, pca_samples)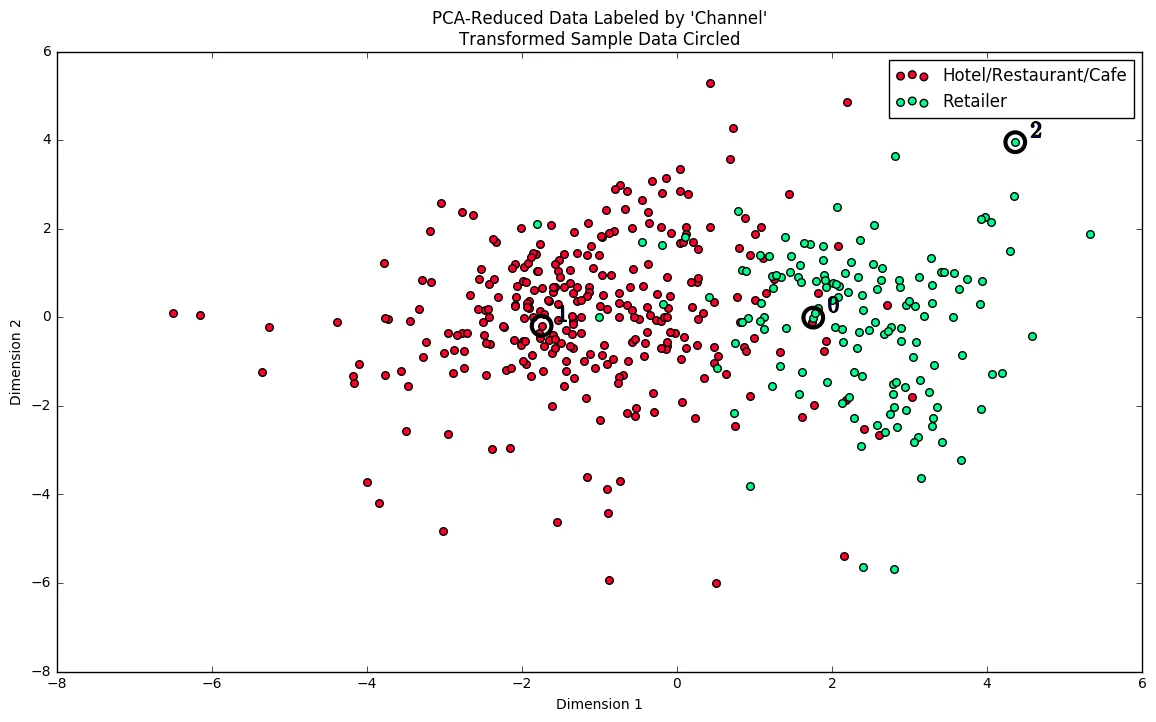
Question 12
How well does the clustering algorithm and number of clusters you’ve chosen compare to this underlying distribution of Hotel/Restaurant/Cafe customers to Retailer customers? Are there customer segments that would be classified as purely ‘Retailers’ or ‘Hotels/Restaurants/Cafes’ by this distribution? Would you consider these classifications as consistent with your previous definition of the customer segments?
Answer:
The GMM model built above for two segments classified the data points in a way very similar to the above plot.
Segment 1 seems to match the restaurants/hotels/cafes very well and Segment 0 matches the retailers very well.
Yes, these classifications are very consistent to the previous definition of the customer segments.