Bike rental ridership prediction using deep learning
I built my first neural network in this project and used it to predict daily bike rental ridership. This involved exploring and processing the data followed by building and training the neural network with the right hyperparameters. Here is the code for this project which was a part of Udacity’s Deep Learning Nanodegree.
Checking out the data
%matplotlib inline%load_ext autoreload%autoreload 2%config InlineBackend.figure_format = 'retina'
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltdata_path = 'Bike-Sharing-Dataset/hour.csv'
rides = pd.read_csv(data_path)rides.head()| instant | dteday | season | yr | mnth | hr | holiday | weekday | workingday | weathersit | temp | atemp | hum | windspeed | casual | registered | cnt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2011-01-01 | 1 | 0 | 1 | 0 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.81 | 0.0 | 3 | 13 | 16 |
| 1 | 2 | 2011-01-01 | 1 | 0 | 1 | 1 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 8 | 32 | 40 |
| 2 | 3 | 2011-01-01 | 1 | 0 | 1 | 2 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 5 | 27 | 32 |
| 3 | 4 | 2011-01-01 | 1 | 0 | 1 | 3 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 3 | 10 | 13 |
| 4 | 5 | 2011-01-01 | 1 | 0 | 1 | 4 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 0 | 1 | 1 |
This dataset has the number of riders for each hour of each day from January 1 2011 to December 31 2012. The number of riders is split between casual and registered, summed up in the cnt column. The first five rows of the data can be seen above.
Below is a plot showing the number of bike riders every hour over the first 10 days or so in the data set. The weekends have lower over all ridership and there are spikes when people are biking to and from work during the week. Looking at the data above, there’s also information about temperature, humidity, and windspeed, all of these likely affecting the number of riders.
rides[:24*10].plot(x='dteday', y='cnt')<matplotlib.axes._subplots.AxesSubplot at 0x7fead7456588>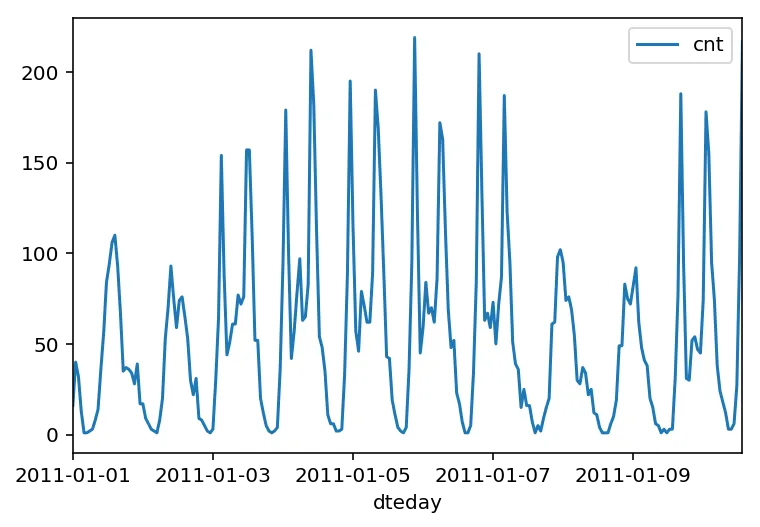
Prepping the data
Dummy variables
Here we have some categorical variables like season, weather, month. To include these in our model, we’ll need to make binary dummy variables. This is simple to do with Pandas thanks to get_dummies().
dummy_fields = ['season', 'weathersit', 'mnth', 'hr', 'weekday']for each in dummy_fields: dummies = pd.get_dummies(rides[each], prefix=each, drop_first=False) rides = pd.concat([rides, dummies], axis=1)
fields_to_drop = ['instant', 'dteday', 'season', 'weathersit', 'weekday', 'atemp', 'mnth', 'workingday', 'hr']data = rides.drop(fields_to_drop, axis=1)data.head()| yr | holiday | temp | hum | windspeed | casual | registered | cnt | season_1 | season_2 | ... | hr_21 | hr_22 | hr_23 | weekday_0 | weekday_1 | weekday_2 | weekday_3 | weekday_4 | weekday_5 | weekday_6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0.24 | 0.81 | 0.0 | 3 | 13 | 16 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0.22 | 0.80 | 0.0 | 8 | 32 | 40 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 0.22 | 0.80 | 0.0 | 5 | 27 | 32 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0.24 | 0.75 | 0.0 | 3 | 10 | 13 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 0 | 0 | 0.24 | 0.75 | 0.0 | 0 | 1 | 1 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
5 rows × 59 columns
Scaling target variables
To make training the network easier, we’ll standardize each of the continuous variables. That is, we’ll shift and scale the variables such that they have zero mean and a standard deviation of 1.
The scaling factors are saved so we can go backwards when we use the network for predictions.
quant_features = ['casual', 'registered', 'cnt', 'temp', 'hum', 'windspeed']# Store scalings in a dictionary so we can convert back laterscaled_features = {}for each in quant_features: mean, std = data[each].mean(), data[each].std() scaled_features[each] = [mean, std] data.loc[:, each] = (data[each] - mean)/stdSplitting the data into training, testing, and validation sets
We’ll save the data for the last approximately 21 days to use as a test set after we’ve trained the network. We’ll use this set to make predictions and compare them with the actual number of riders.
# Save data for approximately the last 21 daystest_data = data[-21*24:]
# Now remove the test data from the data setdata = data[:-21*24]
# Separate the data into features and targetstarget_fields = ['cnt', 'casual', 'registered']features, targets = data.drop(target_fields, axis=1), data[target_fields]test_features, test_targets = test_data.drop(target_fields, axis=1), test_data[target_fields]We’ll split the data into two sets, one for training and one for validating as the network is being trained. Since this is time series data, we’ll train on historical data, then try to predict on future data (the validation set).
# Hold out the last 60 days or so of the remaining data as a validation settrain_features, train_targets = features[:-60*24], targets[:-60*24]val_features, val_targets = features[-60*24:], targets[-60*24:]Building the network
Here is the neural network that will be used to make the predictions. We implemented both the forward pass and backwards pass through the network and then set the hyperparameters - the learning rate, the number of hidden units and the number of training passes.
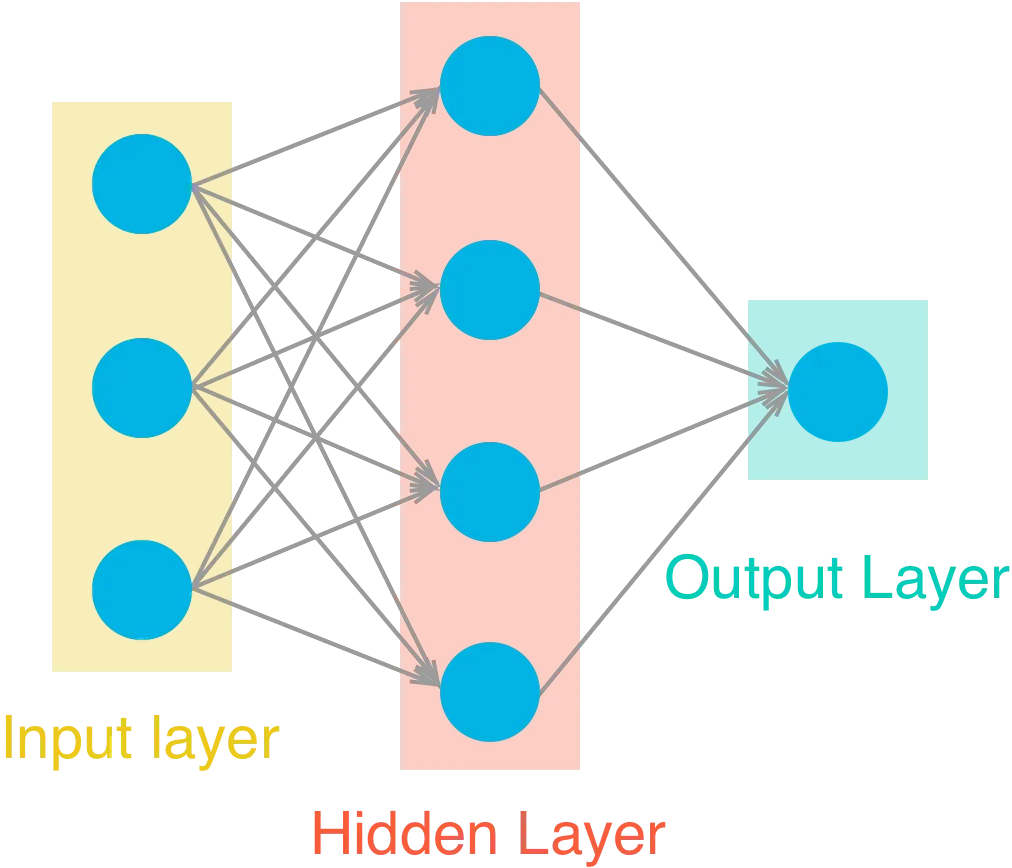
The network has two layers, a hidden layer and an output layer. The hidden layer will use the sigmoid function for activations. The output layer has only one node and is used for the regression, the output of the node is the same as the input of the node. That is, the activation function is $f(x)=x$. A function that takes the input signal and generates an output signal, but takes into account the threshold, is called an activation function. We work through each layer of our network calculating the outputs for each neuron. All of the outputs from one layer become inputs to the neurons on the next layer. This process is called forward propagation.
We use the weights to propagate signals forward from the input to the output layers in a neural network. We use the weights to also propagate error backwards from the output back into the network to update our weights. This is called backpropagation.
Below I completed these tasks:
- Implement the sigmoid function to use as the activation function. Set
self.activation_functionin__init__to your sigmoid function. - Implement the forward pass in the
trainmethod. - Implement the backpropagation algorithm in the
trainmethod, including calculating the output error. - Implement the forward pass in the
runmethod.
from my_answers import NeuralNetworkdef MSE(y, Y): return np.mean((y-Y)**2)Training the network
Here I set the hyperparameters for the network. The strategy here is to find hyperparameters such that the error on the training set is low, but there’s no overfitting. If you train the network too long or have too many hidden nodes, it can become overly specific to the training set and will fail to generalize to the validation set. That is, the loss on the validation set will start increasing as the training set loss drops.
Stochastic Gradient Descent (SGD) is used to train the network. The idea is that for each training pass, we grab a random sample of the data instead of using the whole data set. We use many more training passes than with normal gradient descent, but each pass is much faster. This ends up training the network more efficiently.
Choosing the number of iterations
This is the number of batches of samples from the training data we’ll use to train the network. The more iterations used, the better the model will fit the data. However, this process can have sharply diminishing returns and can waste computational resources if there are too many iterations. You want to find a number here where the network has a low training loss, and the validation loss is at a minimum. The ideal number of iterations would be a level that stops shortly after the validation loss is no longer decreasing. 3000 was a good number after some trial and error.
Choosing the learning rate
This scales the size of weight updates. If this is too big, the weights tend to explode and the network fails to fit the data. Normally a good choice to start at is 0.1; however, if you effectively divide the learning rate by n_records, try starting out with a learning rate of 1. In either case, if the network has problems fitting the data, try reducing the learning rate. Note that the lower the learning rate, the smaller the steps are in the weight updates and the longer it takes for the neural network to converge. After trying out different values, I ended up using a learning rate of 0.6.
Choosing the number of hidden nodes
In a model where all the weights are optimized, the more hidden nodes you have, the more accurate the predictions of the model will be. (A fully optimized model could have weights of zero, after all.) However, the more hidden nodes you have, the harder it will be to optimize the weights of the model, and the more likely it will be that suboptimal weights will lead to overfitting. With overfitting, the model will memorize the training data instead of learning the true pattern, and won’t generalize well to unseen data. 15 hidden nodes produced the best results for me in this case.
import sys
####################### Set the hyperparameters in you myanswers.py file #######################
from my_answers import iterations, learning_rate, hidden_nodes, output_nodes
N_i = train_features.shape[1]network = NeuralNetwork(N_i, hidden_nodes, output_nodes, learning_rate)
losses = {'train':[], 'validation':[]}for ii in range(iterations): # Go through a random batch of 128 records from the training data set batch = np.random.choice(train_features.index, size=128) X, y = train_features.ix[batch].values, train_targets.ix[batch]['cnt']
network.train(X, y)
# Printing out the training progress train_loss = MSE(network.run(train_features).T, train_targets['cnt'].values) val_loss = MSE(network.run(val_features).T, val_targets['cnt'].values) sys.stdout.write("\rProgress: {:2.1f}".format(100 * ii/float(iterations)) \ + "% ... Training loss: " + str(train_loss)[:5] \ + " ... Validation loss: " + str(val_loss)[:5]) sys.stdout.flush()
losses['train'].append(train_loss) losses['validation'].append(val_loss)Progress: 100.0% ... Training loss: 0.090 ... Validation loss: 0.160plt.plot(losses['train'], label='Training loss')plt.plot(losses['validation'], label='Validation loss')plt.legend()_ = plt.ylim()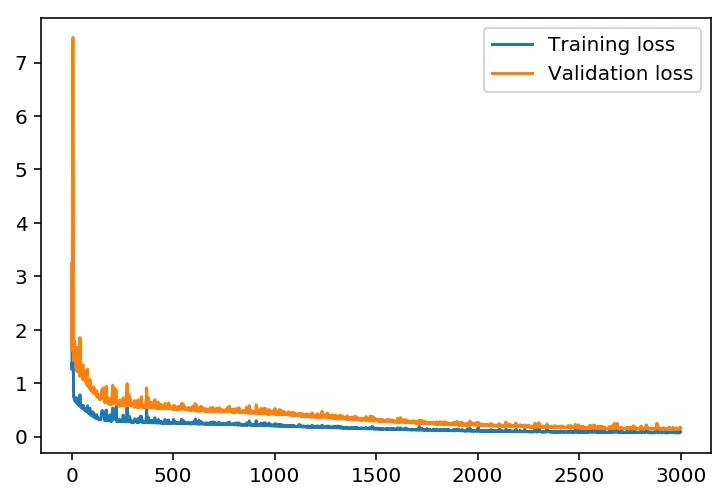
Checking out the predictions
Here, the test data is used to view how well the network is modeling the data.
fig, ax = plt.subplots(figsize=(8,4))
mean, std = scaled_features['cnt']predictions = network.run(test_features).T*std + meanax.plot(predictions[0], label='Prediction')ax.plot((test_targets['cnt']*std + mean).values, label='Data')ax.set_xlim(right=len(predictions))ax.legend()
dates = pd.to_datetime(rides.ix[test_data.index]['dteday'])dates = dates.apply(lambda d: d.strftime('%b %d'))ax.set_xticks(np.arange(len(dates))[12::24])_ = ax.set_xticklabels(dates[12::24], rotation=45)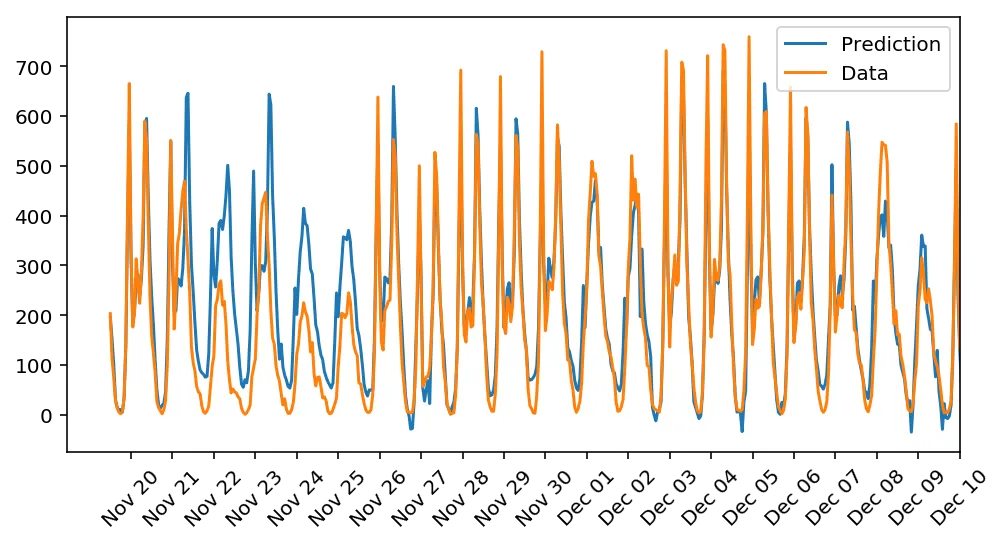
The model does a great job with the predictions as most of the predictions are very close to the actual data except for the days between Nov 21 and Nov 25. This is likely due to the difference in behavior of the people around Thanksgiving.